
Takeaways from the 2016 Neo4j GraphDays: Chicago Conference
graph-databases neo4j As a developer, my favorite part of my job is that I get (and am encouraged) to play around with all kinds of new technologies to test for instances where we could add a new tool to Rightpoint’s ever-expanding toolbox. One of my latest finds is called Neo4j, an industry leader in the Graph Database space. While technically the product has been around for nine years, it seems that they’re just starting to become broadly relevant within the mainstream technology market.
It has been a while since I started tinkering with Neo4j, and today I got the opportunity to attend a Neo4j-sponsored Graph Database conference in Chicago. I would like to share a few learnings for those who want a TL;D[Attend] of the action. Firstly, let’s dive into a bit of quick context.
What is a Graph Database?
A Graph Database is essentially a NoSQL database with the addition of relationships as first-class citizens. A Graph is made up of Nodes and Relationships, which are entities that are described by Labels (which can be neatly compared to Types in other contexts) and can each contain Properties. Think of it this way:
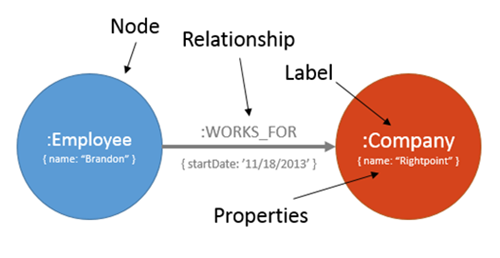
Coming from a onetime SQL Server developer, this is an exciting paradigm because Neo4j’s becoming-less-proprietary Cypher query language allows not only indexable, key-value lookups like we’d expect from a NoSQL technology, but additionally the ability to query data using flexible patterns. The power here lies within the fact that once certain key nodes are identified, traversing their relationships (synonymous with SQL joins) is nearly trivial over large data sets, which amounts to massive performance gains with highly-connected data.
Main Takeaways
The event was full of background on Neo4j, discussion about under which scenarios to choose a Graph Database over NoSQL or RDBMS (and when not to), examples of use cases within a few different industries, and some good examples of simple data models. Here are a few of my favorite points:
When should I use a Graph Database?
This was a great topic because it answered my more architectural curiosities that I’ve had since starting to implement sample projects. In the event, they showed a spectrum between that of Discrete Data and Connected Data, not unlike the following diagram:
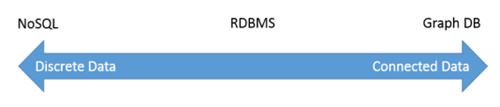
Thinking about RDBMS as the middle ground between NoSQL and Graph really lends more credit to where Graph lives. It makes sense: NoSQL is designed for speed, and it doesn’t have any built-in considerations for relationships between data. SQL Server does have relationship-like capabilities, but let’s face it – foreign keys feel like an afterthought on top of what’s truly a data store meant to house tabular data. This places Graph over in the right wing of being purely built from the start to handle relationships first and foremost.
Aside from that, they made one additional distinction between RDBMS and Graph, which lies within the inherent data structure use cases: relational databases are best at well-known data structures and are unlikely to change over time; conversely, Graph is better for dynamic, prototypical models that are likely to evolve over the lifetime of the application without causing breaking changes. The safety of rigidity or the fluidity of schema flexibility are the keys here.
Neo4j is performance-forward
One of Neo4j’s primary selling points (albeit an expensive one – see my comments later on about licensing) is that the system makes the impossible possible. Classically, when database queries traverse relationships, it’s by performing table seeks/scans on pre-indexed records. When we self-join, like in the case of hierarchical data, we end up recursively performing these operations, which leads to exponential response time increase (bad) when increasing a data set.
Where Neo4j wins here is that instead of having to perform the same seeks/scans, Nodes and Relationships are stored with pointers to related Relationships and Nodes respectively. Algorithmically, when we traverse data that would otherwise require a join, Neo4j can complete 3-4 million of these “pointer-following operations” per second which leads to a relatively flat response time regardless of the data set. This means that where your RDBMS might have taken in the tens-of-minutes to complete a complex, highly-connected query, Neo4j might return the same results in the order of milliseconds. And by the way, the cypher query is likely 10% the amount of code as your SQL query, and 10x more legible (therefore maintainable).
Their given example is that such instances might enable pattern-based financial fraud detection systems to identify fraud before a transaction has even ended, let alone what previously would have been caught weeks after the case. This saves financial institutions billions of dollars in the real world, which is a huge ROI on the cost of Neo4j. Speaking of which…
Licensing
Neo4j is offered in two discrete editions: Community and Enterprise. Community is their free, open source version that operates under the GPL v3 license. Check with your lawyer, but as I understood it from talking to a few Neo4j folks, you’re free to use this under-featured version however you want, provided that you’re not packaging it up closed source and selling it. This means that Community is effectively only useful for a single database instance per server, which might be enough for your project.
The flip side is that the Enterprise license has significantly more features and scalability options, which might make this your only choice regardless of your intent to sell your solution as a product. For example, the Enterprise edition allows for High-Availability scaling features like database clustering, which is a must for business-critical applications that can’t go down when a server fails. Additionally, it allows for a far more robust Hot Backup feature that allows you take backups of your database while it’s online; Community only allows file system backup when the service is offline. Other differences between the editions can be found here.
The feature disparity wouldn’t be worth noting except that Neo4j is clearly the most mature player in the field, and that commands a steep dollar premium. Their Enterprise licenses are based on the number of deployable instances and a few other factors, which can easily push your annual licensing fee over $100K to get the High-Availability features. For their top-tier enterprise license, it’s over $200K/year. Then again, some use cases could easily surpass that value in ROI, but I’ll leave that up to you to decide.
Conclusion
Neo4j has come a long way over the last ten years: they have 200+ enterprise subscriptions – including around 50 of the Global 2000 – and over 2M downloads that are currently pacing at around 50K/mo. I have been very impressed by the speed and ease-of-use of the database so far, and now after attending the conference, I have been able to better wrap my head around why not only anyone would want to use Neo4j, but how it can enable your business to react with speed and efficiency that otherwise wouldn’t be possible with other database paradigms.
It will be exciting watching them continue to grow. They’ve made a fan of me!
Share this post!